
Научная электронная библиотека
Монографии, изданные в издательстве Российской Академии Естествознания

ТЕХНОЛОГИЯ РАЗРАБОТКИ ПРИКЛАДНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Соловьев С. В., Цой Р. И., Гринкруг Л. С.,
OLAP И МНОГОМЕРНЫЕ БАЗЫ ДАННЫХ
Введение
Трудно найти в компьютерном мире человека, который интуитивно не понимал бы, что такое базы данных и зачем они нужны. В отличие от традиционных реляционных СУБД концепция OLAP не так широко известна, хотя термин кубы OLAP слышали, наверное, многие. Что же такое Online Analytical Processing (OLAP)? OLAP - это не отдельно взятый программный продукт, не язык программирования и даже не конкретная технология. Если постараться охватить OLAP во всех его проявлениях, то это совокупность концепций, принципов и требований, лежащих в основе программных продуктов, облегчающих аналитикам доступ к данным.
Технология комплексного многомерного анализа данных получила название OLAP. OLAP - это ключевой компонент организации хранилищ данных. Концепция OLAP была описана в 1993 году Эдгаром Коддом, известным исследователем баз данных и автором реляционной модели данных (E.F. Codd, S.B. Codd, and C.T. Salley, Providing OLAP (on-line analytical processing) to user-analysts: An IT mandate. Technical report, 1993). Первоначально OLAP использовался как профессиональное слово, обозначающее принципиальное отличие от OLTP (Online Transaction Processing - оперативная обработка транзакций). Буква T была заменена на A, что подчеркивало аналитические возможности OLAP в отличие от транзакционных характеристик технологии реляционных баз данных. Сегодня термин OLAP - это понятие для различных технологий, включая системы поддержки принятия решений, Business Intelligence и управленческие информационные системы.
В 1993 г. Е.Ф. Кодд с партнерами опубликовали статью, инициированную компанией Arbor Software (сегодня это Hyperion Solutions), озаглавленную «Обеспечение OLAP (оперативной аналитической обработки) для пользователей-аналитиков», как некий мандат информационной технологии.
Эта статья включала 12 правил, которые теперь хорошо известны. В 1995 году к ним были добавлены еще шесть (которые известны в значительно меньшей степени). Доктор Кодд разбил на четыре группы эти правила, назвав их особенностями. Ниже дано краткое описание этих особенностей.
Основные особенности (B) F1: Многомерное концептуальное представление данных (Оригинальное правило 1). Эта особенность - сердцевина OLAP.
F2: Интуитивное манипулирование данными (Оригинальное правило 10). Чтобы манипулирование данными осуществлялось посредством прямых действий над ячейками в режиме просмотра без использования меню и множественных операций.
F3: Доступность (Оригинальное правило 3). OLAP как посредник. OLAP в качестве прослойки между гетерогенными источниками данных и представлением для конечного пользователя.
F4: Пакетное извлечение против интерпретации (Новое). Это правило требует, чтобы продукт в равной степени эффективно обеспечивал доступ, как к собственному хранилищу данных, так и к внешним данным. Это соответствует определению гибридных OLAP, которые становятся наиболее популярной архитектурой.
F5: Модели анализа OLAP (Новое). OLAP продукты поддерживают все четыре модели анализа, которые Кодд описывает в своей статье (Категориальный, Толковательный, Умозрительный и Стереотипный). Сегодня их можно назвать как формирование параметрически настраиваемых отчетов, формирование разрезов и группировок с обращением, анализом в стиле «что, если» и моделями поиска целей, соответственно. Все OLAP инструменты поддерживают первые два (хотя некоторые поддерживают второй не в полной мере), большинство поддерживают третий в той или иной степени, и лишь некоторые поддерживают четвертый в отдельных полезных расширениях.
F6: Архитектура «клиент-сервер» (Оригинальное правило 5). Чтобы продукт был не только клиент-серверным, но и чтобы серверный компонент был бы достаточно интеллектуальным для того, чтобы различные клиенты могли подключаться с минимумом усилий и программирования. Это требование существенно сильнее, чем просто архитектура клиент-сервер, и относительно небольшое количество продуктов удовлетворяют ему.
F7: Прозрачность (Оригинальное правило 2). Это очень сильное требование. Полное соответствие ему означает, что пользователь электронной таблицы способен получить все необходимые данные из OLAP -
машины, даже не подозревая, откуда они, в конечном счете, берутся. Чтобы выполнить это, продукт должен обеспечивать непосредственный живой доступ к гетерогенным источникам данных и одновременно иметь встроенную полнофункциональную электронную таблицу.
F8: Многопользовательская поддержка (Оригинальное правило 8). Не все OLAP приложения работают только в режиме чтения данных, и этим правилом Кодд указывает стратегическое направление развития. Инструменты OLAP должны обеспечивать одновременный доступ (чтение и запись), интеграцию и конфиденциальность. Специальные особенности (S) F9: Обработка ненормализованных данных (Новое). Оно указывает на необходимость интеграции между OLAP-машиной и ненормализованными источниками данных. То есть модификации данных, выполненные в среде OLAP, не должны приводить к изменениям данных, хранимых в исходных внешних системах.
F10: Сохранение результатов OLAP: хранение их отдельно от исходных данных (Новое). Кодд придерживается распространенного мнения о том, что OLAP приложения, работающие в режиме чтения-записи не должны воздействовать напрямую на обрабатываемые данные. И данные, модифицированные в OLAP, должны сохраняться отдельно от данных транзакций.
F11: Исключение отсутствующих значений (Новое). Все отсутствующие значения отбрасываются в представлении, определенном версией 2 реляционной модели данных.
F12: Обработка отсутствующих значений (Новое). Все отсутствующие значения будут игнорироваться OLAP анализатором без учета их источника. Эта особенность связана с F11 и является почти неизбежным следствием того, как OLAP - машина обрабатывает все данные. Особенности представления отчетов (R) F13: Гибкость формирования отчетов (Оригинальное правило 11). Требует, чтобы измерения могли быть размещены в отчете так, как это нужно пользователю.
F14: Стандартная производительность отчетов (Оригинальное правило 4). Требует, чтобы производительность формирования отчетов существенно не падала с ростом количества измерений и размеров базы данных.
F15: Автоматическая настройка физического уровня (Замена оригинального правила 7). Требует, чтобы OLAP системы автоматически настраивали свою физическую схему в зависимости от типа модели, объемов данных и разреженности базы данных. Управление измерениями (D) F16: Универсальность измерений (Оригинальное правило 6). Все измерения должны быть равноправны, каждое измерение должно быть эквивалентно и в структуре и в операционных возможностях. Практика показала, что это наиболее спорное правило из всех 12 первоначальных (оригинальных) правил.
F17: Неограниченное число измерений и уровней агрегации (Оригинальное правило 12). В случае ограничения Кодд предлагает принятие некоторого максимума, который должен обеспечивать, по крайней мере, 15 измерений, а предпочтительнее - 20. Технически нет продукта, который мог бы соответствовать этому требованию, потому что нет неограниченного объекта на ограниченном компьютере. В любом случае, немного приложений нуждается в более чем 8 или 10 измерениях. Немного приложений имеют иерархию более шести консолидированных уровней. F18: Неограниченные операции между размерностями (Оригинальное правило 9). Все виды операций должны быть дозволены для любых измерений, а не только для измерений типа «показатель» (мера).
Основная функция OLAP - управление измерениями, которые применяются для моделирования основных характеристик бизнеса.
Управлять этими измерениями несложно, во-первых, потому что манипулирование выполняется с помощью графического интерфейса. Во-вторых, внесенные изменения переносятся на все задействованные данные, хранящиеся в базе данных OLAP. В этом состоит коренное отличие от электронных таблиц, поскольку при их использовании необходимо отдельно изменять каждую модель.
Наконец, с помощью OLAP можно легко создавать и рассматривать альтернативные отношения. При использовании же электронных таблиц одновременный просмотр всех измерений невозможен. В этом случае, данные, скорее всего, поступали бы в виде иерархии связанных электронных таблиц, причем каждая таблица более высокого уровня консолидировала и суммировала бы информацию таблиц более низкого уровня. Поскольку такие электронные таблицы оказываются несвязанными и не обеспечивают прозрачность всей модели, чрезвычайно сложно модифицировать модель в приемлемые временные сроки. Возможность визуального моделирования иерархий и управления ими, а также отображения различных представлений отношений между элементами измерений, является неоспоримым пре- имуществом OLAP.
OLAP - это технология, которой могут воспользоваться множество пользователей, работающих на различных платформах. Благодаря тому, что данные хранятся в одном месте - OLAP-кубе, к данным и информации могут одновременно обращаться многие пользователи, не зависимо от их местонахождения.
В 1995 году на основе требований, изложенных Коддом, был сформулирован так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information - быстрый анализ разделяемой многомерной информации), включающий следующие требования к приложениям для многомерного анализа:
Fast (Быстрый) - предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа;
Analysis (Анализ) - возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде;
Shared (Разделяемый) - многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа;
Multidimensional (Многомерный) - многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (это ключевое требование OLAP);
Information (Информация) - приложение должно иметь возможность обращаться к любой нужной информации, независимо от ее объема и места хранения.
Следует отметить, что OLAP - функциональность может быть реализована различными способами, начиная с простейших средств анализа данных в офисных приложениях и заканчивая распределенными аналитическими системами, основанными на серверных продуктах.
Для начала выясним, зачем аналитикам надо специально облегчать доступ к данным. Дело в том, что аналитики - это особые потребители корпоративной информации. Задача аналитика - находить закономерности в больших массивах данных. Поэтому аналитик не будет обращать внимания на отдельно взятый факт, ему нужна информация о сотнях и тысячах подобных событий. Одиночные факты в базе данных могут заинтересовать, к примеру, бухгалтера или начальника отдела продаж, в компетенции которого находится сделка. Аналитику одной записи мало. Ему, к примеру, могут понадобиться все сделки данного филиала или представительства за месяц, год. Заодно аналитик отбрасывает ненужные ему подробности вроде ИНН покупателя, его точного адреса и номера телефона, индекса контракта и тому подобного. В то же время данные, которые требуются аналитику для работы, обязательно содержат числовые значения - это обусловлено самой сущностью его деятельности.
Централизация и удобное структурирование - это далеко не все, что нужно аналитику. Ему ведь еще требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого хранилища, лишены одного - гибкости. Их нельзя покрутить, развернуть или свернуть, чтобы получить желаемое представление данных. Конечно, можно вызвать программиста, и он сделает новый отчет достаточно быстро - в течение часа или трех. Получается, что аналитик может проверить за день не более двух идей. А ему (если он хороший аналитик) таких идей может приходить в голову по нескольку в час. И чем больше срезов и разрезов данных аналитик видит, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых срезов. Вот бы ему такой инструмент, который позволил бы разворачивать и сворачивать данные просто и удобно! В качестве такого инструмента и вы- ступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще применяется для анализа накопленных в этом хранилище сведений. Компоненты, входящие в типичное хранилище, представлены на рис. 50.
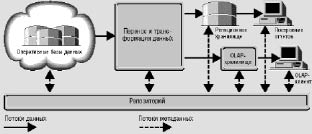
Рис. 50. Структура хранилища данных
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т.е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Подытоживая, можно определить OLAP как совокупность средств многомерного анализа данных, накопленных в хранилище. Теоретически средства OLAP можно применять и непосредственно к оперативным данным или их точным копиям (чтобы не мешать оперативным пользователям). Хранилища данных
Что такое хранилище данных
Информационные системы масштаба предприятия, как правило, содержат приложения, предназначенные для комплексного многомерного анализа данных, их динамики, тенденций и т.п. Такой анализ в конечном итоге призван содействовать принятию решений. Нередко эти системы так и называются - системы поддержки принятия решений.
Принять любое управленческое решение невозможно, не обладая необходимой для этого информацией, обычно количественной. Для этого необходимо создание хранилищ данных (Data warehouses), то есть процесс сбора, отсеивания и предварительной обработки данных с целью предоставления результирующей информации пользователям для статистического анализа (а нередко и создания аналитических отчетов). Ральф Кимбалл (Ralph Kimball), один из авторов концепции хранилищ данных, описывал хранилище данных как место, где люди могут получить доступ к своим данным (Ralph Kimball, The Data Warehouse Toolkit: Practical Techniques for Building Dimensional Data Warehouses, John Wiley & Sons, 1996 и «The Data Web house Toolkit: Building the Web-Enabled Data Warehouse», John Wiley & Sons, 2000). Он же сформулировал и основные требования к хранилищам данных:
поддержка высокой скорости получения данных из хранилища;
поддержка внутренней непротиворечивости данных;
возможность получения и сравнения так называемых срезов данных (slice and dice);
наличие удобных утилит просмотра данных в хранилище;
полнота и достоверность хранимых данных;
поддержка качественного процесса пополнения данных.
Удовлетворять всем перечисленным требованиям в рамках одного и того же продукта зачастую не удается. Поэтому для реализации хранилищ данных обычно используется несколько продуктов, одни из которых представляют собственно средства хранения данных, вторые - средства их извлечения и просмотра, третьи - средства их пополнения и т.д.
Типичное хранилище данных, как правило, отличается от обычной реляционной базы данных. Во-первых, обычные базы данных предназначены для того, чтобы помочь пользователям выполнять повседневную работу, тогда как хранилища данных предназначены для принятия решений. Например, продажа товара и выписка счета производятся с использованием базы данных, предназначенной для обработки транзакций, а анализ динамики продаж за несколько лет, позволяющий спланировать работу с поставщиками, с помощью хранили- ща данных. Во-вторых, обычные базы данных подвержены постоянным изменениям в процессе работы пользователей, а хранилище данных относительно стабильно: данные в нем обычно обновляются согласно расписанию (например, еженедельно, ежедневно или ежечасно - в зависимости от потребностей). В идеале процесс пополнения представляет собой просто добавление новых данных за определенный период времени без изменения прежней информации, уже находящейся в хранилище. И, в-третьих, обычные базы данных чаще всего являются источником данных, попадающих в хранилище. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Предобработка и очистка данных перед загрузкой в хранилище
Термин OLAP неразрывно связан с термином хранилище данных (Data Warehouse).
Вот определение, сформулированное основателем хранилищ данных Биллом Инмоном: «Хранилище данных - это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений».
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов.
Зачем строить хранилища данных - ведь они содержат заведомо избыточную информацию, которая и так находится в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами, в том числе разрозненностью данных, хранением их в форматах различных СУБД и в разных уголках корпоративной сети. Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах.
Таким образом, задача хранилища - предоставить «сырье» для анализа в одном месте и в простой, понятной структуре. Структура хранилища должна быть простой. Есть еще одна причина, оправдывающая появление отдельного хранилища - сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
Под хранилищем можно понимать не обязательно гигантское скопление данных - главное, чтобы оно было удобно для анализа. Вообще говоря, для маленьких хранилищ предназначается отдельный тер- мин - Data Marts (киоски данных).
При создании хранилищ данных очень мало внимания уделяется очистке поступающей в него информации. Видимо считается, что чем больше размер хранилища, тем лучше. Это порочная практика и лучший способ превратить хранилище данных в свалку мусора. Данные очищать необходимо. Ведь информация разнородна и собирается из различных источников. Именно наличие множеств точек сбора информации делает процесс очистки особенно актуальным.
По большому счету, ошибки допускаются всегда, и полностью избавиться от них не получится. Возможно, иногда есть резон смириться с ними, чем тратить деньги и время на избавление от них. Но, в общем случае, нужно стремиться любым способом снизить количество ошибок до приемлемого уровня. Применяемые для анализа методы и так грешат неточностями, так зачем же усугублять ситуацию?
К тому же нужно учесть психологический аспект проблемы. Если аналитик не будет уверен в цифрах, которые получает из хранилища данных, то будет стараться ими не пользоваться и воспользуется сведениями, полученными из других источников. Тогда для чего нужно такое хранилище? Типы ошибок
Не будем рассматривать ошибки такого рода как несоответствие типов, различия в форматах ввода и кодировках. То есть случаи, когда информация поступает из различных источников, где для обозначения одного и того же факта приняты различные соглашения. Характерный пример такой ошибки - обозначение пола человека. Где-то он обозначается как М/Ж, где-то как 1/0, где-то как True/False. С такого рода ошибками борются при помощи задания правил перекодировки и приведения типов. Такого рода проблемы решаются. Рассмотрим проблемы более высокого порядка, те, которые не решаются такими элементарными способами. Вариантов такого рода ошибок много. Есть к тому же ошибки, характерные только для конкретной предметной области или задачи. Рассмотрим такие, которые не зависят от задачи:
1. Противоречивость информации;
2. Пропуски в данных;
3. Аномальные значения;
4. Шум;
5. Ошибки ввода данных.
Для решения каждой из этих проблем есть отработанные методы. Конечно, ошибки можно править и вручную, но при больших объемах данных это становится довольно проблематично. Поэтому рассмотрим варианты решения этих задач в автоматическом режиме при минимальном участии человека.
Противоречивость информации
Для начала нужно решить, что именно считать противоречием. Определившись, найдем их. Есть несколько вариантов действий:
1. При обнаружении нескольких противоречивых записей, удалять их. Метод простой, а потому легко реализуемый. Иногда этого бывает вполне достаточно. Тут важно не переусердствовать.
2. Исправить противоречивые данные. Можно вычислить вероятность появления каждого из противоречивых событий, и выбрать наиболее вероятный. Это самый грамотный и корректный метод работы с противоречиями.
Пропуски в данных
Серьезная проблема. Большинство методов прогнозирования исходят из предположения, что данные поступают равномерным постоянным потоком. На практике такое встречается редко. Поэтому одна из самых востребованных областей применения хранилищ данных - прогнозирование - оказывается реализованной некачественно или со значительными ограничениями. Для борьбы с этим явлением применяют следующие методы:
1. Аппроксимация. Если нет данных в какой-либо точке, берется ее окрестность и по известным формулам вычисляется значение в этой точке. Соответствующая запись добавляется в хранилище. Это работает для упорядоченных данных.
2. Определение наиболее правдоподобного значения. Для этого берется не окрестность точки, а все данные. Этот метод применяется для неупорядоченной информации, т.е., когда мы не в состоянии определить, что же является окрестностью исследуемой точки.
Аномальные значения
Довольно часто происходят события, которые выбиваются из общей картины. И лучше всего такие значения откорректировать. Это связано с тем, что средства прогнозирования ничего не знают о природе процессов. Поэтому любая аномалия будет восприниматься как совершенно нормальное значение. Из-за этого будет искажаться картина - случайный провал или успех будет считаться зако- номерностью.
Метод борьбы с этим - это робастные оценки, которые устойчивы к сильным возмущениям. Оцениваются имеющиеся данные, которые выходят за допустимые границы, и применяется одно из следующих действий:
1. Значение удаляется.
2. Заменяется на ближайшее граничное значение.
Шум
Почти всегда при анализе мы сталкиваемся с шумами. Шум не несет никакой полезной информации, а лишь мешает четко разглядеть картину. Методов борьбы с этим явлением несколько:
1. Спектральный анализ. Позволяет отсечь высокочастотные составляющие данных. Проще говоря, это частые и незначительные колебания около основного сигнала. Причем, изменяя ширину спектра, можно выбирать, какого рода шум мы хотим убрать.
2. Авторегрессионые методы. Активно применяются при анализе временных рядов и сводятся к нахождению функции, которая описывает процесс плюс шум. Собственно шум после этого можно удалить и оставить основной сигнал.
Ошибки ввода данных
Количество типов такого рода ошибок велико, например, опечатки, сознательное искажение данных, несоответствие форматов, и это еще не считая типовых ошибок, связанных с особенностями работы приложения по вводу данных. Для борьбы с большинством из них есть отработанные методы. Например, перед внесением данных в хранилище можно провести проверку форматов. Можно исправлять опечатки на основе различного рода тезаурусов. Грязные данные представляют собой большую проблему. Фактически они могут свести на нет все усилия по созданию хранилища данных. Причем, речь идет не о разовой операции, а о постоянной работе в этом направлении. Идеальным вариантом было бы создание шлюза, через который проходят все данные, попадающие в хранилище. Описанные выше варианты решения проблем не единственные. Существует достаточно много методов обработки, начиная от экспертных систем и заканчивая нейросетями. Механизмы фильтрации должны стать неотъемлемым атрибутом хранилищ данных. Типичная структура хранилищ данных
Конечной целью использования OLAP является анализ данных и представление результатов этого анализа в виде, удобном для восприятия и принятия решений. Основная идея OLAP заключается в построении многомерных кубов, которые будут доступны для пользовательских запросов. Однако исходные данные для построения OLAP-кубов обычно хранятся в реляционных базах данных. Нередко это специализированные реляционные базы данных (Data Warehouse). В отличие от так называемых оперативных баз данных, с которыми работают приложения, модифицирующие данные, хранилища данных предназначены исключительно для обработки и анализа информации. Поэтому проектируются они так, чтобы время выполнения запросов к ним было минимальным. Обычно данные копируются в хранилище из оперативных БД согласно определенному расписанию.
Типичная структура хранилища данных существенно отличается от структуры обычной реляционной СУБД. Как правило, эта структура денормализована (это позволяет повысить скорость выполнения запросов), поэтому может допускать избыточность данных. Для дальнейших примеров воспользуемся базой данных Northwind, входящей в комплекты поставки Microsoft SQL Server и Microsoft Access. Ее структура данных приведена на рис. 51.
Основными составляющими структуры хранилищ данных являются таблица фактов (fact table) и таблицы измерений (dimension tables).
Таблица фактов
Таблица фактов является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно говорят о четырех наиболее часто встречающихся типах фактов. К ним относятся:
факты, связанные с транзакциями (Transaction facts). Они основаны на отдельных событиях (типичными примерами которых являются телефонный звонок или снятие денег со счета с помощью банкомата);
факты, связанные с «моментальными снимками» (Snapshot facts). Основаны на состоянии объекта (например, банковского счета) в определенные моменты времени, например на конец дня, или месяца. Типичными примерами таких фактов являются объем продаж за день или дневная выручка;
факты, связанные с элементами документа (Line-item facts). Основаны на том или ином документе (например, счете за товар или услуги) и содержат подробную информацию об элементах этого документа (например, количестве, цене, проценте скидки);
факты, связанные с событиями или состоянием объекта (Event or state facts). Представляют возникновение события без подробностей о нем (например, просто факт продажи или факт отсутствия таковой без иных подробностей).
Для примера рассмотрим факты, связанные с элементами документа (в данном случае счета, выставленного за товар).
Таблица фактов, как правило, содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений. Чаще всего это целочисленные значения либо значения типа «дата/время». Таблица фактов может содержать сотни тысяч или даже миллионы записей, и хранить в ней повторяющиеся текстовые описания, как правило, невыгодно. Лучше поместить их в меньшие по объему таблицы измерений. При этом как ключевые, так и некоторые не ключевые поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные.
Рис. 51. Структура базы данных Northwind
Пример таблицы фактов, которая может быть построена на основе базы данных Northwind, приведен на рис. 52.
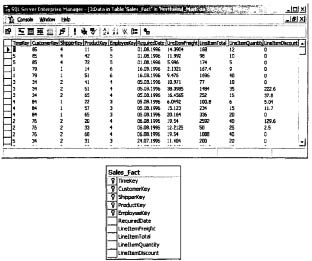
Рис. 52. Пример таблицы фактов
В данном примере измерениям будущего куба соответствуют первые шесть полей, а агрегатным данным - последние четыре.
Для многомерного анализа пригодны таблицы фактов, содержащие как можно более подробные данные, т.е. соответствующие членам (значениям) нижних уровней иерархии соответствующих измерений.
В данном случае предпочтительнее взять за основу факты продажи товаров отдельным заказчикам, а не суммы продаж для разных стран, так как последние все равно будут вычислены OLAP-средством.
Исключение можно сделать для клиентских OLAP-средств - в силу ряда ограничений они не могут манипулировать большими объемами данных.
Отметим, что в таблице фактов нет никаких сведений о том, как группировать записи при вычислении агрегатных данных.
Например, в ней есть идентификаторы продуктов или клиентов, но отсутствует информация о том, к какой категории относится данный продукт или в каком городе находится данный клиент.
Эти сведения, в дальнейшем используемые для построения иерархий в измерениях куба, содержатся в таблицах измерений.
Таблицы измерений
Таблицы измерений содержат неизменяемые, либо редко изменяемые данные. В большинстве случаев эти данные представляют собой по одной записи для каждого члена нижнего уровня иерархии в измерении.
Таблицы измерений содержат как минимум одно описательное поле (обычно с именем члена измерения) и, как правило, целочисленное ключевое поле (обычно это суррогатный ключ) для однозначной идентификации члена измерения. Если будущее измерение, основанное на данной таблице измерений, содержит иерархию, то таблица измерений также может содержать поля, указывающие на «родителя» данного члена в этой иерархии.
Нередко (но не всегда) таблица измерений может содержать поля, указывающие на «прародителей» и иных «предков» в данной иерархии (это обычно характерно для сбалансированных иерархий), а также дополнительные атрибуты членов измерений, содержавшиеся в исходной оперативной базе данных (например, адреса и телефоны клиентов).
Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов.
Отметим, что скорость роста таблиц измерений должна быть незначительной по сравнению со скоростью роста таблицы фактов.
Например, добавление новой записи в таблицу измерений, характеризующую товары, производится только при появлении нового товара, не продававшегося ранее. Пример таблицы измерений приведен на рис. 53.
Одно измерение куба может содержаться как в одной таблице (в том числе и при наличии нескольких уровней иерархии), так и в нескольких связанных таблицах, соответствующих различным уровням иерархии в измерении. Если каждое измерение содержится в одной таблице, такая схема хранилища данных носит название «звезда» (star schema). Пример такой схемы приведен на рис. 54. Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка» (snowflake schema). Пример схемы «снежинка» приведен на рис. 55.
Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним уровням иерархии измерения, и находящиеся в соотношении «один ко многим» в главной таблице измерений, соответствующей нижнему уровню иерархии, иногда называют консольными таблицами (outrigger table).
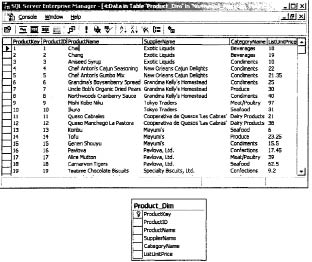
Рис. 53. Пример таблицы измерений
Отметим, что даже при наличии иерархических измерений, с целью повышения скорости выполнения запросов к хранилищу данных, нередко предпочтение отдается схеме «звезда».
Однако не все хранилища данных проектируются по двум приведенным выше схемам. Часто вместо ключевого поля для измерения, содержащего данные типа «дата», и соответствующей таблицы измерений, сама таблица фактов может содержать ключевое поле типа «дата». В этом случае соответствующая таблица измерений просто отсутствует.
В случае несбалансированной иерархии (например, которая может быть основана на таблице Employees базы данных Northwind, имеющей поле Employee ID, которое одновременно является и первичным и внешним ключом и отражает подчиненность одних сотрудников другим (рис. 55)) в схему «снежинка» следует вносить коррективы. В этом случае обычно в таблице измерений присутствует связь, аналогичная соответствующей связи в оперативной базе данных.
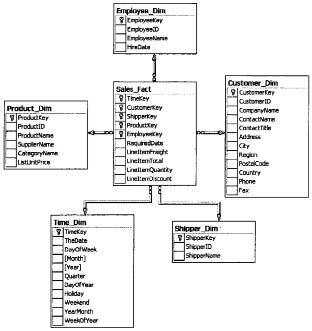
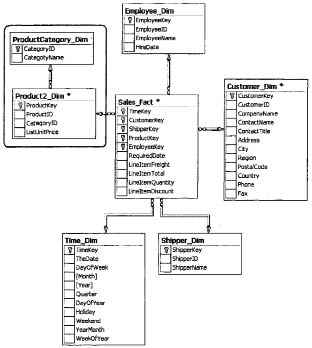
Рис. 55. Пример схемы «снежинка»
Выше отмечалось, таблица измерений может содержать поля, не имеющие отношения к иерархиям и представляющие собой просто дополнительные атрибуты членов измерений (member properties). Иногда такие атрибуты могут быть использованы при анализе данных.
Следует сказать, что для создания реляционных хранилищ данных нередко применяются специализированные СУБД, хранение данных в которых оптимизировано с точки зрения скорости выполнения запросов. Примером такого продукта является Sybase Adaptive Server IQ, реализующий нетрадиционный способ хранения данных в таблицах (не по строкам, а по столбцам). Однако создавать хранилища можно и в обычных реляционных СУБД. OLAP на клиенте и на сервере
Многомерный анализ данных может быть произведен с помощью различных средств, которые условно можно разделить на клиентские и серверные OLAP-средства. Клиентские OLAP-средства представляют собой приложения, осуществляющие вычисление агрегатных данных (сумм, средних величин, максимальных или минимальных значений) и их отображение. При этом сами агрегатные данные содержатся в кэше внутри адресного пространства такого OLAP-средства.
Если исходные данные содержатся в настольной СУБД, вычисление агрегатных данных производится самим OLAP-средством. Если источник исходных данных серверная СУБД, многие из клиентских OLAP-средств посылают на сервер SQL запросы, содержащие оператор GROUP BY, и в результате получают агрегатные данные, вычисленные на сервере.
Как правило, OLAP-функциональность реализована средствами статистической обработки данных (из продуктов этого класса на российском рынке широко распространены продукты компаний Stat Soft и SPSS) и в некоторых электронных таблицах. В частности, неплохими средствами многомерного анализа обладает Microsoft Excel 2000. С помощью этого продукта можно создать и сохранить в виде файла небольшой локальный многомерный OLAP-куб и отобразить его двух или трехмерные сечения.
Многие средства разработки содержат библиотеки классов или компонентов, позволяющие создавать приложения, реализующие простейшую OLAP-функциональность (например, компоненты Decision Cube в Borland Delphi и Borland C++Builder). Помимо этого многие компании предлагают элементы управления ActiveX и другие библиотеки, реализующие подобную функциональность.
Отметим, что клиентские OLAP-средства применяются, как правило, при малом числе измерений (обычно рекомендуется не более шести) и небольшом разнообразии значений этих параметров. Ведь полученные агрегатные данные должны умещаться в адресном пространстве подобного средства, а их количество растет экспоненциально при увеличении числа измерений. Поэтому даже самые примитивные клиентские OLAP-средства, как правило, позволяют произвести предварительный подсчет объема требуемой оперативной памяти для создания в ней многомерного куба.
Многие клиентские OLAP-средства позволяют сохранить содержимое кэша с агрегатными данными в виде файла, что, в свою очередь, позволяет не производить их повторное вычисление. Отметим, что нередко такая возможность используется для отчуждения агрегатных данных с целью передачи их другим организациям или для публикации. Типичным примером таких отчуждаемых агрегатных данных является статистика заболеваемости в разных регионах и в различных возрастных группах, которая является открытой информацией, публикуемой министерствами здравоохранения различных стран и Всемирной организацией здравоохранения. При этом собственно исходные данные, представляющие собой сведения о конкретных случаях заболеваний, являются конфиденциальными данными медицинских учреждений, которые ни в коем случае не должны попадать в руки страховых компаний и, тем более, становиться достоянием гласности.
Идея сохранения кэша с агрегатными данными в файле получила свое дальнейшее развитие в серверных OLAP-средствах, в которых сохранение и изменение агрегатных данных, а также поддержка содержащего их хранилища осуществляются отдельным приложением или процессом, называемым OLAP-сервером. Клиентские приложения могут запрашивать подобное многомерное хранилище и в ответ получать данные. Некоторые клиентские приложения могут также создавать такие хранилища или обновлять их в соответствии с изменившимися исходными данными. Преимущества применения серверных OLAP-средств по сравнению с клиентскими OLAP-средствами сходны с преимуществами применения серверных СУБД по сравнению с настольными. В случае применения серверных средств вычисление и хранение агрегатных данных происходят на сервере, а клиентское приложение получает лишь результаты запросов к ним, что позволяет в общем случае снизить сетевой трафик, время выполнения запросов и требования к ресурсам, потребляемым клиентским приложением. Средства анализа и обработки данных масштаба предприятия, как правило, базируются именно на серверных OLAP-средствах, например, таких как Oracle Express Server, Microsoft SQL Server 2000, Analysis Services, Hyperion Essbase, продуктах компаний Crystal Decisions, Business Objects, Cognos, SAS Institute.
Многие клиентские OLAP-средства (в частности, Microsoft Excel 2000, Seagate Analysis и др.) позволяют обращаться к серверным OLAP-хранилищам, выступая в этом случае в роли клиентских приложений, выполняющих подобные запросы. Технические аспекты многомерного хранения данных
В многомерных хранилищах данных содержатся агрегатные данные различной степени подробности, например, объемы продаж по дням, месяцам, годам, по категориям товаров и т.п. Цель хранения агрегатных данных - сократить время выполнения запросов, поскольку в большинстве случаев для анализа и прогнозов интересны не детальные, а суммарные данные. Поэтому при создании многомерной базы данных всегда вычисляются и сохраняются некоторые агрегатные данные.
Однако сохранение всех агрегатных данных не всегда оправданно. При добавлении новых измерений объем данных, составляющих куб, растет экспоненциально (иногда говорят о «взрывном росте» объема данных). Если говорить более точно, степень роста объема агрегатных данных зависит от количества измерений куба и членов измерений на различных уровнях иерархий этих измерений. Для решения проблемы «взрывного роста» применяются разнообразные схемы, позволяющие при вычислении, далеко не всех возможных агрегатных данных, достичь приемлемой скорости выполнения запросов.
Как исходные, так и агрегатные данные могут храниться либо в реляционных, либо в многомерных структурах. Поэтому в настоящее время применяются три способа хранения данных:
MOLAP (Multidimensional OLAP) - исходные и агрегатные данные хранятся в многомерной базе данных. Хранение данных в многомерных структурах позволяет манипулировать данными как многомерным массивом, благодаря чему скорость вычисления агрегатных значений одинакова для любого из измерений. Однако в этом случае многомерная база данных оказывается избыточной, так как многомерные данные полностью содержат исходные реляционные данные;
ROLAP (Relational OLAP) - исходные данные остаются в той же реляционной базе данных, где они изначально и находились. Агрегатные же данные помещают в специально созданные для их хранения служебные таблицы в той же базе данных;
HOLAP (Hybrid OLAP) - исходные данные остаются в той же реляционной базе данных, где они изначально находились, а агрегатные данные хранятся в многомерной базе данных.
Некоторые OLAP-средства поддерживают хранение данных только в реляционных структурах, некоторые - только в многомерных. Однако большинство современных серверных OLAP-средств поддерживают все три способа хранения данных. Выбор способа хранения зависит от объема и структуры исходных данных, требований к скорости выполнения запросов и частоты обновления OLAP-кубов.
Большинство современных OLAP-средств не хранит «пустых» значений (примером «пустого» значения может быть отсутствие продаж сезонного товара вне сезона). Многомерное представление информации. Кубы OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации. Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей - измерений (Dimensions) находятся данные, количественно характеризующие процесс - меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т.п. Пользователь, анализирующий информацию, может разрезать куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.
В качестве мер в трехмерном кубе, изображенном на рис. 56, использованы суммы продаж, а в качестве измерений - время, товар и магазин. Измерения представлены на определенных уровнях группировки: товары группируются по категориям, магазины - по странам, а данные о времени совершения операций - по месяцам.
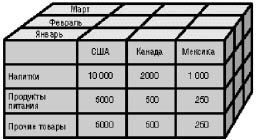
Рис. 56. Пример куба
Разрезание куба
Даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер. Что уж говорить о кубах с количеством измерений, большим трех. Для визуализации данных, хранящихся в кубе, применяются, как правило, привычные двумерные, т.е. табличные представления, имеющие сложные иерархические заголовки строк и столбцов.
Двумерное представление куба можно получить, разрезав его поперек одной или несколькими осями (измерениями): т.е. фиксируем значения всех измерений, кроме двух, и получаем двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) представлено одно измерение, в вертикальной (заголовки строк) - другое, а в ячейках таблицы - значения мер. При этом набор мер фактически рассматривается как одно из измерений. Выбираем для показа или одну меру (и тогда можем разместить в заголовках строк и столбцов два измерения), или показываем несколько мер (и тогда одну из осей таблицы займут названия мер, а другую - значения единственного неразрезанного измерения). На рис. 57 изображен двумерный срез куба для одной ме- ры - Unit Sales (продано штук) и двух неразрезанных измерений - Store (Магазин) и Время (Time).
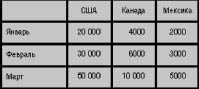
Рис. 57. Двумерный срез куба для одной меры
На рис. 58 представлено лишь одно неразрезанное измерение - Store, но зато отображаются значения нескольких мер - Unit Sales (продано штук), Store Sales (сумма продажи) и Store Cost (расходы магазина).

Рис. 58. Двумерный срез куба для нескольких мер
Двумерное представление куба возможно и тогда, когда неразрезанными остаются более двух измерений. При этом на осях среза (строках и столбцах) будут размещены два или более измерений разрезаемого куба (рис. 59).

Рис. 59. Двумерный срез куба с несколькими измерениями на одной оси
Метки
Значения, откладываемые вдоль измерений, называются членами или метками (members). Метки используются как для разрезания куба, так и для ограничения (фильтрации) выбираемых данных, когда в измерении, остающемся неразрезанным, нас интересуют не все значения, а их подмножество, например три города из нескольких десятков. Значения меток отображаются в двумерном представлении куба как заголовки строк и столбцов.
Иерархии и уровни
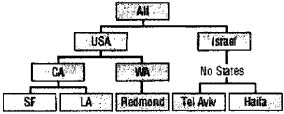
Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней (levels). Например, метки измерения Магазин (Store) естественно объединяются в иерархию с уровнями:
All (Мир)
Country (Страна)
State (Штат)
City (Город)
Store (Магазин).
В соответствии с уровнями иерархии вычисляются агрегатные значения, например, объем продаж для USA (уровень Country) или для штата California (уровень State). В одном измерении можно реализовать более одной иерархии, например, для времени: {Год, Квартал, Месяц, День} и {Год, Неделя, День}.
Иерархии могут быть сбалансированными (balanced), как, например, иерархия, представленная на рис. 60, а также иерархии, основанные на данных типа «дата-время», и несбалансированными (unbalanced). Типичный пример несбалансированной иерархии - иерархия типа «начальник- подчиненный», представлен на рис. 61.
Иногда для таких иерархий используется термин Parent-child hierarchy.
Рис. 60. Иерархия в измерении, связанном с географическим положением клиентов
Рис. 61. Несбалансированная иерархия
Существуют также иерархии, занимающие промежуточное положение между сбалансированными и несбалансированными (обозначаются термином ragged - неровный). Обычно они содержат такие члены (рис. 62), логические родители которых находятся не на непосредственно вышестоящем уровне. Например, в географической иерархии есть уровни Country, City и State, но при этом в наборе данных имеются страны, не имеющие штатов или регионов между уровнями Country и City.
Несбалансированные и «неровные» иерархии поддерживаются не всеми OLAP-средствами. Например, в Microsoft Analysis Services 2000 поддерживаются оба типа иерархии, а в Microsoft OLAP Services 7.0 - только сбалансированные. Различным в разных OLAP-средствах может быть число уровней иерархии, максимально допустимое число членов одного уровня, максимально возможное число самих измерений. Архитектура OLAP приложений
Все, что говорилось выше про OLAP, по сути, относилось к многомерному представлению данных.
Многомерность в OLAP-приложениях может быть разделена на три уровня:
1. Многомерное представление данных - средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными. Слой многомерного представления абстрагирован от физической структуры данных и воспринимает данные как многомерные.
2. Многомерная обработка - средство (язык) формулирования многомерных запросов (традиционный реляционный язык SQL здесь оказывается непригодным) и процессор, умеющий обработать и выполнить такой запрос.
3. Многомерное хранение - средства физической организации данных, обеспечивающие эффективное выполнение многомерных запросов.
Первые два уровня в обязательном порядке присутствуют во всех OLAP-средствах. Третий уровень, хотя и является широко распространенным, не обязателен, так как данные для многомерного представления могут извлекаться и из обычных реляционных структур; процессор многомерных запросов в этом случае транслирует многомерные запросы в SQL-запросы, которые выполняются реляционной СУБД.
Конкретные OLAP-продукты, как правило, представляют собой либо средство многомерного представления данных OLAP-клиент (Pivot Tables в Excel 2000 фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД OLAP-сервер (Oracle Express Server или Microsoft OLAP Services).
Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы Microsoft.
Подводя итог сказанному выше, можно отметить следующее:
назначение хранилищ данных - это предоставление пользователям информации для статистического анализа и принятия управленческих решений;
хранилища данных должны обеспечивать высокую скорость получения данных, возможность получения и сравнения, так называемых срезов данных, а также непротиворечивость, полноту и достоверность данных;
OLAP (On-Line Analytical Processing) является ключевым компонентом построения и применения хранилищ данных. Эта технология основана на построении многомерных наборов данных - OLAP-кубов, оси которого содержат параметры, а ячейки - зависящие от них агрегатные данные;
приложения с OLAP-функциональностью должны предоставлять пользователю результаты анализа за приемлемое время, осуществлять логический и статистический анализ, поддерживать многопользовательский доступ к данным, осуществлять многомерное концептуальное представление данных и иметь возможность обращаться к любой нужной информации.
MRP, ERP... Что дальше?
Каковы основные этапы развития информационных систем управления? В чем ограничения новейших классов систем ERP и OLAP? Можно ли построить современную корпоративную систему управления на базе одного программного приложения? Каковы возможные пути дальнейшего развития информационных систем? История - наука о будущем. Первыми программными продуктами, в той или иной степени автоматизирующими бизнес-операции, были, так называемые Автоматизированные Рабочие Места. Само по себе, появление АРМов было революцией. Потому что такие рутинные операции, как бухгалтерский учет, учет материальных запасов - все это было доверено компьютерам, которые, как мы знаем, делают это гораздо быстрее, лучше и точнее, чем человек.
Следующая ступень эволюции - интеграция разрозненных АРМов в единые комплексные системы. Результаты таких объединений были названы MRP. MRP - это Material Requirements Planning, т.е. система, позволяющая планировать потребности предприятия в ресурсах, и, позволяющая делать так, чтобы эти потребности были вовремя удовлетворены, необходимые комплектующие пошли в производство и заказ был выполнен в установленный срок. Естественно, развитие систем управления на этом не остановилось, и в 90-х годах прошлого столетия все большую популярность стали завоевывать приложения ERP-класса. В основу идеологии ERP (Enterprise Resource Planning) заложено более широкое представление о ресурсах предприятия: и материальные потоки, денежные средства, труд рабочих. То есть все то, что предприятие потребляет и чем оперирует для достижения своей главной цели - получения прибыли. ERP-приложения - это мощные продукты, лучшие представители которых охватывают практически все сферы деятельности предприятий. Перечень модулей и функций таких приложений достаточно широк: бухгалтерский учет, маркетинг, разные виды производства, финансовые операции, управление цепочками поставок и т.д. Однако если внимательно проанализировать историю их использования, зачастую приходится делать одни и те же выводы:
1. Внедрение ERP-приложений занимает очень много времени.
2. Одно эксплуатируемое ERP-приложение в большинстве случаев не охватывает полностью все участки предприятия.
3. Имеющихся в ERP-приложениях аналитических средств не достаточно, чтобы обрабатывать накапливаемую информацию.
Безусловно, предприятие, внедрившее у себя ERP-систему, имеет конкурентное преимущество перед теми, у кого до сих пор используются разрозненные и не связанные между собой АРМы. Информация и... геометрия. Практически параллельно с развитием ERP развивались приложения, предназначенные для анализа и обработки информации в реальном режиме времени (OLAP-системы). Такие системы обладают гибкостью представления и обработки данных. Интуитивно, пользователи-аналитики потянулись именно к тем приложениям, структура которых наиболее полно соответствует представлению человека о природе информации. Например, пытаясь представить себе динамику объемов продаж компании по месяцам в разрезе видов продукции, мы представляем двумерную таблицу. Та же информация, но в разрезе регионов - опять двумерная таблица. Но если попытаться увидеть и регионы, и виды продукции, то возникает необходимость сложить эти две таблицы. Если заранее известно, что нас заинтересуют и регионы по каждому виду, и каждый вид в разрезе регионов, то возникает трехмерная модель данных, каждое из измерений которой становится равноправным в своем существовании. Трехмерная модель наиболее наглядно представляется в виде куба. Но перегрузка воображения наступает в момент, когда мы пытаемся к кубу добавить еще одно измерение - какой-либо дополнительный атрибут статистики продаж: продавец, заказчик и т.п.
Считается, что любая OLAP-система состоит из многомерных OLAP-кубов. Плюс OLAP - предоставление пользователю возможности самостоятельной интерактивной работы с отчетами. То есть пользователь сам подбирает комбинацию измерений, получая результат сначала на экране компьютера, а затем в печатном виде. С момента внедрения в организации подобного инструмента происходит стремительное снижение потребностей пользователей в услугах служб автоматизации. Уже не надо никому заказывать необходимый отчет и затем долго его отлаживать и согласовывать. Можно сделать этот отчет самому. Здесь проявляется преимущество OLAP-систем по сравнению с ERP. Независимость от внутренней службы автоматизации гораздо быстрее удовлетворяет руководство компании аналитическими возможностями Информационной Системы. Менеджмент предприятия получает возможность получения корпоративной информации непосредственно из системы, становясь менее зависимым от тех, кто раньше эту информацию готовил. Как результат, менеджерский состав оказывается непосредственно вовлеченным в развитие информационных технологий своего предприятия. А участие руководства в процессе построения информационной системы является решающим фактором успеха проекта автоматизации. Многие продвинутые пользователи персональных компьютеров, старающиеся максимально использовать все богатство возможностей программы Excel, используют в качестве кубов перекрестные таблицы. Человечество изначально стремилось анализировать большие объемы сложных по своей структуре данных с помощью системы координат. Математики предпочитают называть кубы многомерными матрицами. А одним из последних примеров «бумажного куба» можно назвать знаменитую «шахматку» - таблицу, в которой строками и столбцами являются бухгалтерские счета. С помощью «шахматки» можно анализировать обороты по каждому счету (взятому из строки таблицы) в разрезе корреспонденции с другими счетами (взятыми из столбцов). Новый термин. Многие OLAP-производители начали создавать специализированные версии для автоматизации управленческих задач бюджетом, финансового планирования, анализа и контроля. Международная компания IDC, специализирующаяся на независимом мониторинге рынка ПО, объединила такие приложения в новое семейство - BPM (Business Performance Management - Управление Эффективностью Бизнеса). BPM-системы позволяют связывать воедино такие понятия как миссия компании, стратегия развития, цели, долгосрочные планы, среднесрочные перспективы и конкретные бюджеты на ближайший период. Система позволяет видеть и использовать в своей работе отчетность смежных подразделений: на основе планов поставок сырья, оценивать возможности по объемам производства и т.п. Откорректированные и дополненные на нижнем уровне цифры агрегируются до общекорпоративного уровня. Процесс бюджетного планирования итерируется, пока не будет составлен наиболее оптимальный бюджет.
Специализированные компьютерные системы класса BPM позволяют вести несколько версий бюджета или финансового плана организации и, при необходимости, оперативно переключать все структурные подразделения на новую версию. Интеграция. На рис. 63 представлена диаграмма интеграции специализированных программных приложений, позволяющая примерно оценить применимость приложений в зависимости от размера предприятия.
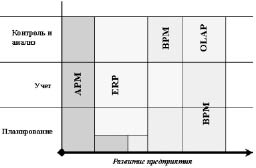
Рис. 63. Диаграмма интеграции программных приложений
АРМ - автоматизированные рабочие места. В данном контексте могут представлять собой комплексную систему, состоящую или из отдельных подсистем, или из какого-то стержневого приложения низшего по отношению к ERP класса, или из электронных таблиц Excel.
ERP (Enterprise Resource Planning) - информационная система управления ресурсами предприятия. В системах такого класса ведется операционный (управленческий) и бухгалтерский учет, осуществляются функции производственного планирования и планирования поставок (Axapta, Baan, J.D. Edwards, R/3).
BPM (Business Performance Management) - информационная система, предназначенная для автоматизации процессов управленческого планирования и контроля. Такое приложение является, по сути, OLAP-системой с характеристиками ERP (возможность многопользовательского ввода информации, поддержка исполнения бизнес-процессов, потоков работ и регламентов). Например, Comshare MPC, Planning, Hyperion Pillar, Oracle Financial Analyzer.
OLAP - средство аналитической обработки данных в реальном режиме времени. В отличие от BPM, OLAP-приложения не предназначены ни на какие конкретные задачи, хотя некоторые формы встроенной бизнес-логики (готовые аналитические отчеты, перечень бизнес-объектов и т.п.) в этих приложениях иногда присутствует (BusinessObjects, Essbase, Oracle Express, SAS).
Как видно из рисунка, главное в интеграционном процессе - это оценка текущего размера предприятия и взвешенный баланс выбираемых для его автоматизации приложений. Немаловажно, чтобы каждое приложение имело возможность расширения - на перспективу. Цель представления интеграционной диаграммы заключается в отведении каждому классу своей роли.
Резюме
1. История развития программных приложений проходит через следующие стадии: АРМ, MRP, ERP и OLAP.
2. Функциональными ограничениями ERP-приложений являются: долгий срок внедрения; не полный охват подразделений; минимум аналитических возможностей; не включение топ менеджмента в работу с системой управления.
3. Для анализа данных применяются программные приложения класса OLAP. Эти приложения строятся на основе многомерного представления данных, которое наиболее четко соответствует представлению человека об окружающем мире.
4. Функциональными ограничениями OLAP-приложений являются: специализация на анализе свершившихся событий - без элементов прогнозирования; отсутствие возможности построения «куба-отчета-формы».
5. В теории управления существуют задачи (например, бюджетное или финансовое планирование), в которых все три фазы управления - планирование, учет и контроль - перекрываются во времени и выполняются практически одновременно. На решении этих задач специализируются программные приложения класса BPM, созданные на базе OLAP-технологий, но обладающие так же рядом свойств ERP-приложений.
6. BPM-приложения автоматизируют в первую очередь управленческие функции: стратегическое управление, бюджетное и финансовое планирование, консолидацию, управленческую отчетность и анализ.
7. Простота в освоении и интуитивный интерфейс позволяют руководителям предприятий самостоятельно работать с корпоративной системой, построенной на базе BPM-приложения.
8. Наиболее логичный подход к построению корпоративной системы управления - интегрировать приложения ERP, BPM и OLAP. Чтобы правильно определять пропорции использования таких приложений, предприятию необходимо четко оценивать свой текущий и планируемый уровень развития.
9. Порядок внедрения программных приложений должен соответствовать последовательности фаз управления. В первую очередь необходимо охватить процессы планирования, затем учета и только потом автоматизацией функций управленческого анализа. Сходство и различия двух подходов
к архитектуре хранилищ данных
Рассмотрим два принципиальных подхода к архитектуре хранилищ данных: с архитектурой шины (BUS) и корпоративная информационная фабрика (CIF).
Оба подхода направлены на создание одного объекта - корпоративного хранилища данных. Соответственно, единство конечного объекта означает общность требований, которым должен удовлетворять любой подход для достижения конечного результата, а это, в свою очередь, указывает на то, что и в самой архитектуре должны быть общие черты. Первое основное требование связано с тем, что для принятия и осуществления важных решений, варьирующих от проблем выживания бизнеса до увеличения прибыли, все корпорации нуждаются в программном средстве для хранения, анализа и интерпретации данных, которые они накапливают. Для достижения своих целей корпорации должны в полной мере использовать возможности первичных данных, что, в свою очередь, требует соответствующих операционных систем и систем обратной связи.
Именно для этого создаются хранилища данных. И оба архитектурных подхода в полной мере отвечают названным требованиям. Второе требование - это требование точности и своевременности данных. Каждый пользователь должен иметь возможность доступа к любым данным в соответствии со своими конкретными требованиями, и этот доступ должен осуществляться с помощью легко понятных и простых способов построения запросов.
Как хранилище данных с архитектурой шины (BUS), так и корпоративная информационная фабрика (CIF) вполне удовлетворяют и второй группе требований.
В техническом отношении обе архитектуры признают необходимость наличия в хранилище как атомарных, так и суммарных данных, а также то, что данные обеих категорий должны быть доступны пользователям для анализа. Различия. Первое существенное отличие между этими архитектурами - различные подходы к построению баз данных, составляющих основу Хранилища. Если Ральф Кимболл (Ralph Kimball) использует пространственную организацию баз данных (dimensional data bases) c архитектурой звезда как на стадии подготовки, так и презентации данных, то Билл Инмон (Bill Inmon) комбинирует два подхода. В его модели атомарные данные организованы в реляционные базы и находятся в нормализованном хранилище данных, причем суммарные данные доступны для использования через специализированные хранилища, средства data mining и OLAP. Что же касается зависимых витрин данных, то только они организованы с помощью пространственных моделей, как и у Ральфа Кимболла.
Таким образом, архитектуры отличаются только способами обращения с атомарными данными: их пространственной организацией у Кимболла и нормализованной - у Инмона. Второе принципиальное отличие этих двух подходов, отчасти вытекающее из первого, - вопрос физической организации хранилища. Если у Инмона хранилище данных - это физически целостный реально существующий объект, то хранилище Кимболла - скорее виртуальный объект. Это коллекция витрин данных, которые могут быть пространственно разобщенными.
Этими двумя основными отличиями в целом и исчерпывается принципиальная разница между той и другой моделью. Преимущества и недостатки. Возникает вопрос: чья модель лучше? Очевидно, что он не имеет однозначного ответа. В целом, оба этих подхода сходятся в главном - в необходимости современных средств управления информационными потоками для принятия своевременных и обоснованных решений при ведении бизнеса и, соответственно, в необходимости создания соответствующих структур для хранения данных, их координации и интеграции. Выбор того или иного технического решения определяется нуждами бизнеса и его конкретными особенностями.
Преимущества и недостатки каждого из подходов напрямую вытекают из их архитектурных решений. Считается, что пространственная организация с архитектурой звезда облегчает доступ к данным и требует меньше времени на выполнение запросов, а также упрощает работу с атомарными данными. С другой стороны, сторонники подхода Билла Инмона критикуют эту схему за отсутствие необходимой гибкости и уязвимость структуры, полагая, что в пространственно организованные атомарные данные труднее вносить необходимые изменения.
Реляционная схема организации атомарных данных замедляет доступ к данным и требует больше времени для выполнения запросов в силу разной организации атомарных и суммарных данных. Но, с другой стороны, эта схема предоставляет широкие возможности для манипулирования атомарными данными, изменения их формата и способа представления по мере необходимости.
Подводя итог, можно сказать, что, несмотря на кажущиеся глубокие различия между двумя подходами к архитектуре хранилищ данных, это различия в основном технического плана. А в целом хранилища обоих типов оказываются достаточно похожими по своим функциям и задачам, которые можно решать с их помощью. Гибридный подход. Некоторые организации используют так гибридный подход, стараясь совместить лучшее, что есть в обоих методах. Как видно из рис. 64, гибридное хранилище данных совмещает рассмотренные модели. Оно включает нормализованное хранилище CIF и пространственное хранилище атомарных и суммарных данных на основе архитектуры шины Кимболла BUS.
Если в организации сначала было создано нормализованное хранилище данных, а потом возникла необходимость в развитии возможностей представления данных, чтобы продемонстрировать их ценность, то гибридный подход поможет выгодно использовать уже сделанные инвестиции.
Аналитические системы и хранилища данных
В общем виде технология функционирования любой корпоративной информационно-аналитической системы состоит в следующем.
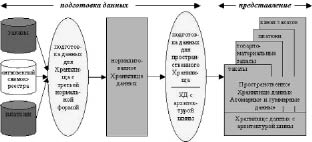
Рис. 64. Гибрид нормализованного и пространственного хранилищ данных
Данные поступают из различных внутренних транзакционных систем, от подчиненных структур, от внешних организаций в соответствии с установленным регламентом, формами и макетами отчетности. Вся эта информация проверяется, согласуется, преобразуется и помещается в хранилище и витрины данных. После этого пользователи с помощью специализированных инструментальных средств получают необходимую им информацию для построения различных табличных и графических представлений, прогнозирования, моделирования и выполнения других аналитичес- ких задач.
Основными функциями информационно-аналитической системы являются:
извлечение данных из различных источников, их преобразование и загрузка в хранилище;
хранение данных;
анализ данных, включая регламентированные отчеты, произвольные запросы, многомерный анализ (OLAP) и извлечение знаний (data mining).
Обычно для выполнения этих функций используются различные продукты, что приводит к усложненной архитектуре системы, необходимости интегрировать разнородные инструментальные среды, дополнительным затратам на администрирование, проблемам согласования данных и метаданных на различных серверах.
Корпорация Oracle предлагает новый подход к созданию аналитических систем - единую и функционально полную платформу для решения всех перечисленных задач.
Основой решения является система управления базами данных Oracle9i Database, с помощью которой можно не только надежно хранить огромные объемы аналитической информации, но и эффективно выполнять процедуры извлечения данных из разнородных источников, согласовывать, агрегировать и преобразовывать эти данные в аналитическую информацию, загружать ее в хранилище. Кроме того, средствами этого продукта поддерживаются различные методы анализа данных, включая многомерный анализ, прогнозирование, поиск закономерностей. Все эти функции реализуются описанными ниже специальными компонентами Oracle9i: Компонент Data Warehouses объединяет возможности сервера Oracle, которые предназначены для построения и эффективного использования хранилищ данных. Режимы функционирования базы данных для аналитических задач коренным образом отличаются от ситуации в системах транзакционной обработки (OLTP). Они требуют специальных настроек параметров, методов индексирования и обработки запросов. Начиная с Oracle 7, в СУБД Oracle стали появляться новые средства, с помощью которых совершенствовалась работы базы в режиме хранилищ и витрин данных. К их числу относятся параллельная обработка запросов, позволяющая наиболее полно использовать возможности многопроцессорных аппаратных платформ, эффективные битовые (bitmap) индексы и специализированные алгоритмы выполнения запросов, такие как кэш-соединения (hash joins), которые многократно повысили производительность обработки аналитических запросов. В СУБД Oracle имеется мощная возможность секционирования данных (partitioning), облегчающая управление и значительно ускоряющая обработку больших таблиц и индексов. Кроме того, появились новые схемы оптимизации, преобразующие запросы к типу звезда, что позволяет избежать ресурсоемкого полного соединения справочных таблиц. Одним из важнейших усовершенствований в этом направлении является технология управления суммарными данными на основе материализованных представлений (materialized views). Анализируя статистику работы системы, СУБД рекомендует администратору необходимые агрегаты, автоматически их создает и периодически обновляет. Затем при выполнении запросов с агрегированием система автоматически переписывает их таким образом, чтобы они обращались к суммарным данным, хранящимся в материализованных представлениях. Такой подход иногда на несколько порядков повышает производительность хранилища данных для конечных пользователей. Среди других технологий, связанных с быстродействием в аналитических задачах, - функциональные индексы, специальные операции для вычисления итогов в отчетах, широкий спектр встроенных аналитических функций и ряд других. ETL компонент - это расширение стандартных средств СУБД Oracle дополнительными командами и средствами, полезными для задач сбора и преобразования данных. К таким средствам относятся внешние таблицы, автоматическая фиксация изменения данных (change data capture), табличные функции, одновременный ввод и корректировка данных, ввод данных в несколько таблиц и др. Опция OLAP Services позволяет хранить и обрабатывать многомерную информацию на сервере баз данных, где находится реляционное хранилище. По функциональным возможностям OLAP Services сравнимы с многомерной СУБД Oracle Express и, по-существу, завершают процесс интеграции технологии Oracle Express c реляционным сервером Oracle Database. Средства OLAP Services поддерживают в полном объеме основной язык сервера Express, а для существующих баз данных Express обеспечивается их миграция в СУБД Oracle.
Средствами опции Oracle9i Data Mining реализуется технология data mining, с помощью которой в больших объемах информации можно автоматически выявить закономерности и взаимосвязи, полезные для принятия управленческих решений.
Для разработки и развертывания хранилищ и витрин данных предназначен Oracle Warehouse Builder, который представляет собой интегрированную CASE-среду, ориентированную на создание информационно-аналитических систем. Средствами этого продукта можно проектировать, создавать и администрировать хранилища и витрины данных, разрабатывать и генерировать процедуры извлечения, преобразования и загрузки данных из различных источников, эффективно управлять метаданными. Стандарты Common Warehouse Model, лежащие в основе репозитория Oracle Warehouse Builder, обеспечивают его интеграцию с различными аналитическими инструментальными средствами как Oracle, так и других фирм.
Для организации доступа с рабочих мест аналитиков к данным хранилища и витрин используются специализированные рабочие места, поддерживающие необходимые технологии как оперативного, так и долговременного анализа. Современный подход к инструментальным средствам анализа не ограничивается использованием какой-то одной технологи. В настоящее время принято различать четыре основных вида аналитической деятельности:
стандартная отчетность;
нерегламентированные запросы;
многомерный анализ (OLAP);
извлечение знаний (data mining).
Каждая из этих технологий поддерживается продуктами Oracle: для стандартной отчетности используется Oracle Reports, для формирования нерегламентированных отчетов и запросов - Oracle Discoverer, для сложного многомерного анализа - опция сервера Oracle9i OLAP Services вместе с JDeveloper и BI Java Beans или линия продуктов Oracle Express, а для задач извлечения знаний- опция Oracle Data Mining.
Важнейшей чертой аналитических инструментальных средств и приложений Oracle является их готовность к работе в среде Web. В этом случае менеджеры и аналитики могут получать информацию из хранилищ и витрин данных в защищенной Интранет-архитектуре с помощью сервера приложений Oracle9i Application Server.
Кроме собственно продуктов, обеспечивающих полное решение для корпоративной информационно-аналитической системы, корпорация Oracle предлагает оригинальную методологию выполнения проекта по созданию и сопровождению таких систем. Эта методология называется Data Warehouse Method (DWM) и является частью общего подхода Oracle к проектированию и реализации различных проектов.
Совместное использование учетных систем и технологии OLAP
Без систем управления базами данных не обходится практически ни одна организация, особенно среди тех, которые традиционно ориентированы на взаимодействие с клиентами. Банки, страховые компании, авиа- и прочие транспортные компании, сети супермаркетов, телекоммуникационные и маркетинговые фирмы, организации, занятые в сфере услуг и другие - все они собирают и хранят в своих базах гигабайты данных о клиентах, продуктах и сервисах. Эти сведения применяются для различных целей, например для управления материально-техническими запасами, управления отношениями с клиентами (CRM - customer relationship management), биллинга (формирования счетов) и т.п.
Такие базы данных называют операционными или транзакционными, поскольку они характеризуются огромным количеством небольших транзакций, или операций записи-чтения. Компьютерные системы, осуществляющие учет операций и собственно доступ к базам транзакций, принято называть системами оперативной обработки транзакций (OLTP - On-Line Transactional Processing) или учетными системами.
Учетные системы настраиваются и оптимизируются для выполнения максимального количества транзакций за короткие промежутки времени. Как правило, большой гибкости здесь не требуется, и чаще всего используется фиксированный набор надежных и безопасных методов сбора данных и отчетности. Показателем эффективности является количество транзакций, выполняемых за секунду. Обычно отдельные операции очень малы и не связаны друг с другом. Однако каждую запись данных, характеризующую взаимодействие с клиентом (звонок в службу поддержки, кассовую операцию, заказ по каталогу, посещение Web-сайта компании и т.п.) можно использовать для получения качественно новой информации, а именно для создания отчетов и анализа деятельности фирмы. Необходимость использования OLAP в учетных системах. Набор аналитических функций в учетных системах обычно весьма ограничен. Схемы, используемые в OLTP-приложениях, осложняют создание даже простых отчетов, так как данные чаще всего распределены по множеству таблиц, и для их агрегирования необходимо выполнять сложные операции объединения. Как правило, попытки создания комплексных отчетов требуют больших вычислительных мощностей и приводят к потере производительности.
Кроме того, в учетных системах хранятся постоянно изменяющиеся данные. По мере сбора транзакций суммарные значения меняются очень быстро, поэтому два анализа, проведенные с интервалом в несколько минут, могут дать разные результаты. Чаще всего, анализ выполнятся по окончании отчетного периода, иначе картина может оказаться искаженной. Кроме того, необходимые для анализа данные могут храниться в нескольких системах.
Некоторые виды анализа требуют таких структурных изменений, которые недопустимы в текущей оперативной среде. Например, нужно выяснить, что произойдет, если у компании появятся новые продукты. На «живой» базе такое исследование провести нельзя. Следовательно, эффективный анализ редко удается выполнить непосредственно в учетной системе.
Этим объясняется интерес к объединению и анализу данных учетной системы с помощью технологии OLAP. Этот метод позволяет аналитикам, менеджерам и руководителям проникнуть в суть накопленных данных за счет быстрого и согласованного доступа к широкому спектру представлений информации. Исходные данные преобразуются таким образом, чтобы наглядно отразить структуру деятельности предприятия.
При этом конечному пользователю предоставляется ряд аналитических и навигационных функций:
расчеты и вычисления по нескольким измерениям, иерархиям и/или членам;
анализ трендов;
выборка подмножеств данных для просмотра на экране;
углубление в данные (drill down) для просмотра информации на более детальном уровне;
переход к детальным данным, лежащим в основе анализа;
поворот таблицы отображаемых данных. Сравнение технологий. Как правило, учетные системы работают с реляционными базами данных. Для OLAP-приложений разработана специальная многомерная модель, которая позволяет более эффективно использовать данные, накопленные в оперативных системах. Технология оперативной аналитической обработки ориентирована на представление данных в виде массивов. Под массивом понимается последовательность элементов, например продажи продукта по рынкам/временным периодам, или доход по времени/региону.
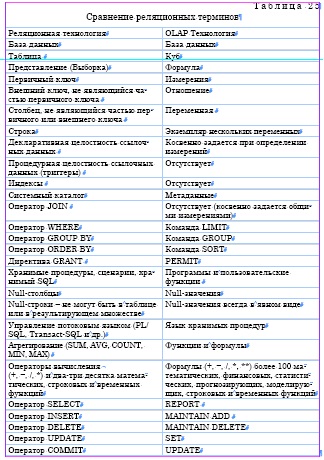
В концепции и терминологии OLAP есть много аналогий с реляционной моделью. В табл. 25 приведено сравнение реляционных терминов и понятий и соответствующих эквивалентов в OLAP.
Необходимо отметить, что различия этих технологий существенны. В табл. 26 приведено сравнение системных характеристик OLTP и OLAP.
Совместное использование OLAP и учетной системы, в частности прямая настройка аналитических функций на OLTP-базу, осложняется несколькими факторами:
OLAP запросы к базам данных чаще всего бывают сложными и требуют много времени. Прямой доступ к OLTP-базе существенно снижает общую производительность оперативной системы;
разнообразные учетные системы неоднородны по типу используемых синтаксических соглашений и концептуальных допущений (единицы измерений, онтологии, наименование, кодирование и т.п.), поэтому их интеграция затруднена;
данные в учетных системах часто зашумленные, неполные и несогласованные;
как правило, нет единой модели данных масштаба предприятия. Кроме того, при проектировании баз учетной системы могут использоваться разные модели данных (иерархическая, реляционная, объектно-ориентированная, плоские файлы, фирменные модели);

в оперативных системах отсутствует метод предоставления данных для конкретных групп пользователей в нужной для них форме;
информация за прошлые периоды теряется при обновлении OLTP-базы (при записи в нее новых, актуальных данных). Это препятствует выполнению анализа временных тенденций, который так важен для многих сфер бизнеса;
в OLTP-базе не хранятся данные в агрегированном, денормализованном виде, что необходимо для оперативной аналитической обработки. А преобразование данных в процессе выполнения запросов оказывается слишком трудоемким.
Кроме перечисленных выше концептуальных различий, существуют еще и технологические проблемы, которые необходимо преодолеть для внедрения аналитических возможностей в учетные системы. Среди них можно назвать следующие: различие в аппаратных платформах (компьютерах, сетях и периферийных устройствах), использование разного программного обеспечения (разнообразных операционных систем, СУБД, языков программирования, протоколов, связующего ПО и т.п.), а также географическое распределение баз данных по всей организации и вне ее. Пути интеграции. Процесс интегрирования OLAP-технологии с учетными системами может осуществляться по-разному. Все подходы имеют свои преимущества и недостатки. Как было сказано выше, прямая настройка аналитических средств (Direct BI) затруднена. Возможно также создание дублированных баз данных, витрин и хранилищ данных. Практически всегда возникает необходимость в преобразовании операционных данных в аналитические. Для создания многомерного представления, нужно настроить данные так, чтобы они соответствовали логической многомерной структуре, далекой от структуры учетной системы. Например, многие измерения, используемые для анализа, могут вообще не иметь соответствий в учетных системах и извлекаться из других источников. Хранилище данных. Хранилище данных - это методология и технология, позволяющая решать проблемы, возникающие при интеграции распределенных и гетерогенных баз учетной системы при внедрении методов OLAP.
Информация в хранилище является предметно-ориентированной, интегрированной, она хранится долговременно, а ее управление осуществляется независимо от исходных операционных баз данных. В отличие от OLTP-баз, где хранятся детальные данные в виде отдельных записей, в хранилище содержится сводная и консолидированная информация (часто из нескольких операционных источников), в том числе и историческая.
Объем данных в хранилище намного больше, чем в базе учетной системы (в тысячи раз). Здесь данные организованы в преагрегированной форме в виде многомерных кубов (гиперкубов), удобных для выполнения аналитических операций. Архитектура хранилища представлена набором компонентов, среди них: источники данных, репозиторий метаданных (здесь описывается, какая информация доступна и где), один или несколько серверов хранилища или центральный репозиторий (который управляет исходными базами и поддерживает многомерные представления данных), а также интерфейсные средства (например, для создания запросов, отчетов и выполнения анализа).
При обновлении все изменения в исходных данных отражаются в хранилище. За счет оперативных средств обратной связи хранилище данных позволяет интегрировать процесс поддержки принятия решений с учетными системами и внешними источниками данных. Совместное использование различных моделей данных. Средства OLAP часто реализуются в виде набора многопользовательских приложений с Web-поддержкой, дают быстрый доступ к любому элементу базы вне зависимости от объема и сложности данных. Часто это достигается за счет использования OLAP-сервера - мощного многопользовательского инструмента для работы с многомерными структурами данных. Конструкция сервера и структура данных оптимизируются таким образом, чтобы можно было выполнять нерегламентированные запросы, а также быстрые, гибкие вычисления и преобразования исходных данных.
С помощью OLAP-сервера может быть организовано физическое хранение обработанной многомерной информации, что позволяет быстро выдавать ответы на запросы пользователя. Кроме того, предусматривается преобразование данных из реляционных и других баз в многомерные структуры в режиме реального времени.
Каким образом реляционные и многомерные средства работают совместно? OLAP-продукты вливаются в существующую корпоративную инфраструктуру путем интегрирования с реляционными системами. Администраторы баз данных либо загружают реляционные данные в многомерный кэш, либо настраивают кэш для доступа к SQL данным.
В табл. 27 приведены сравнительные характеристики различных моделей управления данными.
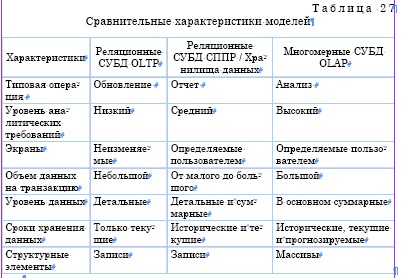
В архитектуре, одновременно использующей реляционные и многомерные системы, данные хранятся на OLAP-сервере, или OLAP-структуры используются в качестве кэша для реляционных данных. Можно использовать комбинацию двух этих подходов, минимизируя объем данных, перемещаемых из реляционной среды в многомерную и обратно.
Обычно в реляционной системе хранятся более детализированные данные, чем в многомерной. OLAP позволяет пользователю переходить от сводной информации к более подробной информации.
Реляционная и многомерная модели математически очень похожи, поэтому отображение из одной архитектуры в другую выполняется легко. Например, переменные OLAP можно получить из столбцов реляционной базы. Измерения многомерного куба связаны напрямую с ключами, идентифицирующими строки реляционной базы.
Модель определяет, что видит пользователь, какие вычислительные функции доступны, как быстро выполняются вычисления, каковы задачи технического персонала.
Обе модели дают возможности анализа, но использование, написание и поддержка сложного аналитического кода в многомерной модели требует меньшего времени и усилий, чем в реляционной.